- Introduction
- Text analytics as the Core
- Sense and Sentiment
- Conclusion
Outline
Introduction
- Data science for Everyone
Data Science
用數據來解決問題/佐證假說/敘說故事
- Data science is only useful when the data are used to
answer a question / tell a story.
- 多型態資料(esp. 數值資料與文本資料)互動是當紅的關注焦點。
- 如何 (從 ptt) 的語言與網路分析/預測鄉民對於某特定政策的 想法/立場/情緒 ?
- 如何從使用者的觀影/購物/閱讀/偏好等行為事件進行 推薦/行銷 ?
Data science in the Humanities
DASH: A new gradute certificate: data management, statistics, text analysis, geospatial analysis, digital prosopography, and data visualization and information design.
Text as Data
非結構性資料
Unstructured data
Natural language is primarily hard because it is messy. There are few rules. And yet we can easily understand each other most of the time.
We are awash with text, from books, papers, blogs, tweets, news, and increasingly text fromspoken utterances.
非結構性資料
Unstructured data
- 多元
- 異質
- 個人與群體差異
- 時空變異
Language and Text
Human language is highly ambiguous … It is also ever changing and evolving. Peopleare great at producing language and understanding language, and are capable of expressing, perceiving, and interpreting very elaborate and nuanced meanings. Atthe same time, while we humans are great users of language, we are also very poorat formally understanding and describing the rules that govern language. (Neural Network Methods in Natural Language Processing, 2017. http://amzn.to/2u0JtPl)
語言有很複雜嗎?
Linguistic Complexity
從處理單位開始就是問題
- sound segments
- character and word
- n-gram (n-word sequences) > lexical bundles / chunks
- sentence, paragraph
- theme
- natural units (a speech, poem, lyrics, manifesto, etc)
[Lab.1] : 中文斷詞(分詞)
- 字與詞
- 為何需要斷詞
- 斷詞系統
[Lab.1] : 中文斷詞
R 套件
library(jiebaR) # 用 worker() 初始化斷詞引擎 seg <- worker() # 各種參數設定情參考 ?worker # 斷詞簡單例子 seg["據台大語言所小編謝舒凱表示,宅宅也是非常用功 der"]
## [1] "據" "台大" "語言所" "小編" "謝舒凱" "表示" "宅宅" ## [8] "也" "是" "非常" "用功" "der"
中文合詞?
seg["你這種人還是死死去最好了"]
## [1] "你" "這種" "人" "還是" "死" "死去" "最好" "了"
跨語言處理其實也沒有想像中的簡單
Morpho-syntax complex
德文複合詞:
Rindfleischetikettierungsberwachungsaufgabenbertragungsgesetz(“the law concerning the delegation of duties for the supervision of cattle marking and the labelling of beef”)土耳其文:
OSMANLILŞTIRAMAYABIĪLECEKLERIĪMIĪZDENMIĪŞSIĪNIĪZCESIĪNE(“as if you were of those whom we might consider not converting into an Ottoman”)
Japanese, Thai, Lao, Khmer
#txt_jp <- "政治とは社会に対して全体的な影響を及ぼし、 #社会で生きるひとりひとりの人の人生にも様々な影響を及ぼす複雑な領域である。" #tokens(txt_jp) txt_khmer <- "តៃវ៉ាន់បោះជំហានឆ្ពោះទៅរកការធ្វើពាណិជ្ជកម្មនៅអាស៊ីដើម្បីកាត់បន្ថយភាពអាស្រ័យលើប្រទេសចិន " #Taiwan Steps up Asia Business to Reduce Dependence on China #taivean baohchomhan chhpaohtow rokkarothveu peanechchokamm now asai daembi #katbanthoy pheap asry leu bratesa chen tokens(txt_khmer)
## tokens from 1 document. ## text1 : ## [1] "តៃវ៉ាន់" "បោះជំហាន" "ឆ្ពោះទៅ" "រកការធ្វើ" "ពាណិជ្ជកម្ម" "នៅ" "អាស៊ី" ## [8] "ដើម្បី" "កាត់បន្ថយ" "ភាព" "អាស្រ័យ" "លើ" "ប្រទេស" "ចិន"
Linguistic and Textual Complexity
- 語彙的多義行為 Polysemy: A word can have multiple senses in varied contexts
- 語彙使用的歧異現象 Ambiguity: lexical, structural, scope (每個人都喜歡他的孩子), anaphora/deictic expressions (他上禮拜開始就應該待在這裡)
Wordnet
- A fine-grained sense inventory and lexical relations database
Chinese Wordnet
中文詞彙網路

詞類 (Parts of speech) 是不一樣的概念
Penn treebank pos tagset

Parts of speech
(Mandarin Chinese Words and Parts of Speech: A Corpus-based Study. 2017. Routledge)

[Lab.2]:語助詞的語意
啊
Textual Complexity
文本本身也有語意邏輯結構
- 文本語流 sense and sentiment flow
- conversational maxim
Rhetorical relations

Affect Complexity
Emotions are at the heart of what it means to be human… we act in the world either volitionally or emotionally.(Mason,2015)
Human Affect
- Emotion: A relatively brief episode of coordinated brain, automatic and behavioural changes that facilitate a response to an external or internal event of significance for the organism.
- Mood: More long-lasting affective state (days to months); more difuse
- Feeling : Subjective representation of emotion, private to individual experiencing them
Affect is a broader all-encompassing term whch refers to general topics of emotion, feelings, and mood together.
Related Affective Phenomena
- Attitude: relatively enduring, affectively coloured beliefs, preferences and predispositions toward objects or persons.
- Temperament: affective styles that are apparent early in life, and
- Personality trait : stable individual difference across different situations.
- Cognition: do not have facial expressions, not always physiological changes, though cognitive arousal can get rise to emotions.
How language use reflects the affect
Near-Synonyms in Chinese
心情,氣質,脾氣,性情,性格,情緒,態度,人格,品行。
Sentiment Analysis (in general)
- Mining opinions and sentiments from natural language / texts (e.g., product review, social media discussion, survery responses)
- It requires a deep understanding of the explicit/implicit, regular/irregular patterns of language use.
- Employing machine learning techniques / dictionary look-up methods to detect the
sentiment polarity, emotion types and valence shifting.
Sentiment analysis in Digital Humanities
- Text mining/analytics
- Literature sentiment
- Political speech
- Historical text
Sentiment analysis in Digital Humanities
political speech

Sentiment dispersion
Harry Potter

Deeper understanding of affective expressions?
- Multimodality affect state (paralinguistics)
- Lexical items vs lexical chunks/bundles
- Sense-sentiment concurrent processing
- Tracing varieties and changes
Multimodality

Sentiment analysis with larger units
affect patterns
- 情緒表達語言的單位是什麼
- 情緒表達和語意表達是否皆具備組合性
Expressive Units of Emotions
Emotion types and Words

Pattern Grammar of Affect
- From Cues to Rules (lee, 2010)
- Local Grammar of Affect (Bednarek. 2008)
- Use pattern grammar (Hunston, 1999) in approaching evaluative (semantic) prosody (Lee and Hsieh, 2016).
Chinese Evaluative Patterns

DeepLEX (Hsieh, 2018): Rationale
- 不同視野下的詞彙行為/知識表徵化
Operationalized lexical knowledge representation
E.g., 我們不(只)關心「打」的詞義有哪些,更關心
在
什麼標準|脈落下「打」的詞義分成幾個;這樣的
標記訊息(Categorical and/or Numerical) 跟該單位在其他脈絡下被觀察到的行為 (習得,情緒,發展,語言教學,神經表徵,心理反應等) 之間的關聯為何?以這樣的第二層知識出發提供「語言學養分」給 NLP/Machine Learning (rather than
shallow linguistic feature engineering)
Reused, Reproduced, Reshaped and Reinforced.
DeepLEX: Assumptions
It takes the functional position (usage-based view) in determining units and patterns (in Chinese), as well as the ontological grounding on the relation between linguistic objects and situations (bits of reality). (Langacker 1987, 1988, 1999; Croft 2002; Tomasello 2003; Bybee 2006, 2010)
Lexical data at different levels are modularized (only for practical reasons), such as syntax-semantics module, emotion module, discourse and pragmatic module, diachronic module, etc. Researchers from different fields can initiate a new cooperation based upon.
Modules
| Hanzi | Semantics | Emotion | Lexical.Age | Aquisition | Social Network | Morpho-syntax | —– |
|---|---|---|---|---|---|---|---|
| phonetics | sense | polarity | 1930.freq | 3y.freq | indegree | POS | —– |
| components | relations | classes | 1940.freq | 4y.freq | outdegree | productivity | —– |
| —— | —— | —– | —– | —– | —– | —– | —– |
At the moment there are 55k units (ranging from characters to lexical chunks) with over than 150 variables. The scope and size are still evolving, with its concerted and long-term efforts we believe this resource will be valuable for deep processing of natural language processing and intelligent applications.
Toward a sense-aware sentiment analysis
Concurrent processing of Word Sense and Sentiment

- 他曾打了勾勾說要娶她當新娘,她可沒忘喔!
- 明天班上有烤肉,不知道要不要去,因為我車票打好了,不太想去改。
- 少爺打了一個寒顫,冷靜的想了很久。
Text analytics
文本分析(text analytics)、語料庫(corpus)、機器學習(machine learning)、自然語言處理(natural lanaguage processing)
文本分析基本流程
鳥瞰
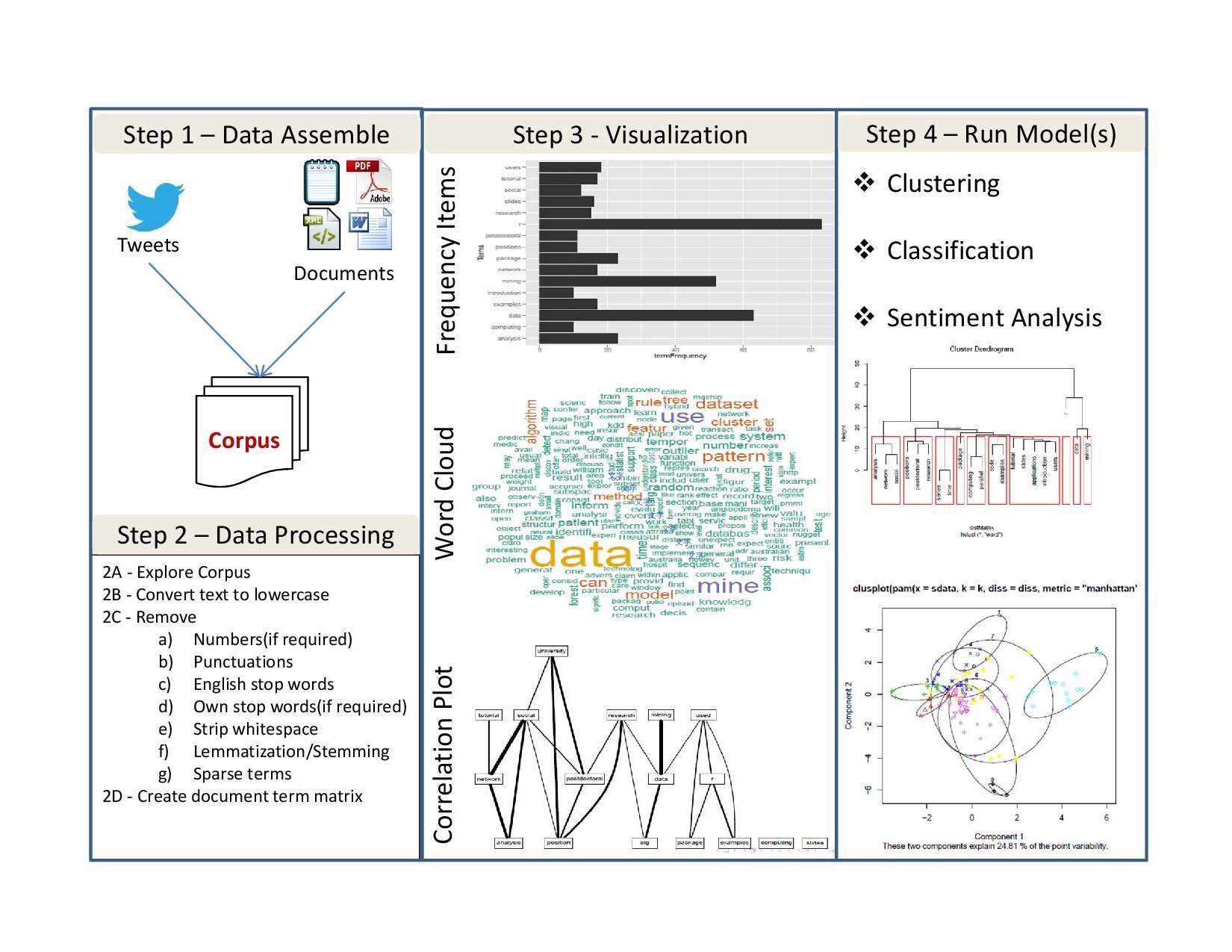
{kind=link}
What is Text Analytics ?
- (WHAT): Text Analytics is the process of converting unstructured text data into meaningful data for analysis
- (WHY) : to measure customer opinions, product reviews, feedback, to provide search facility, sentimental analysis and entity modeling to support fact based decision making, etc.
- (HOW): combining many linguistic, statistical, and machine learning techniques.
What is Text Analytics ?
常見任務
It involves lexical analysis, categorization, clustering, pattern recognition, tagging, annotation, information extraction, link and association analysis, visualization, and predictive analytics. Text Analytics determines key words, topics, category, semantics, tags from the millions of text data available in an organization in different files and formats. The term Text Analytics is roughly synonymous with text mining.
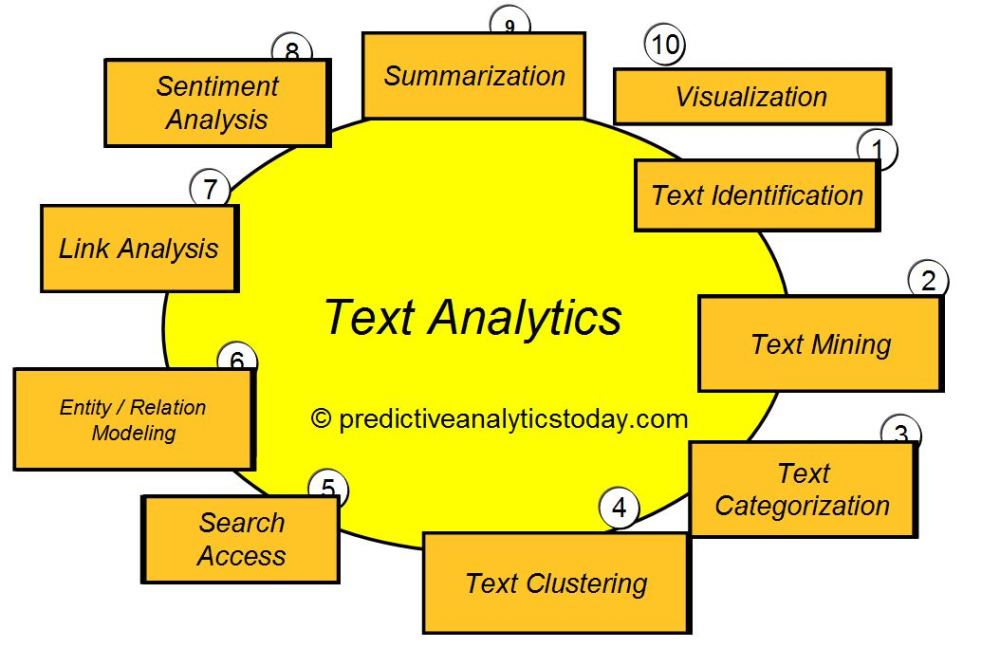
Text analytics
慣用流程
- Preparing / Preprocessing text and data.
- Text is unstructured or partially structured data that must be prepared for analysis. We extract features from text. We define measures.
- Quantitative data are messy or missing, too They may require transformation prior to analysis. Data preparation consumes much of a data scientist’s time.
Exploratory data analysis and Infographics (data visualization for the purpose of discovery. We look for groups in data, find outliers, identify common dimensions, patterns, and trends.)
Prediction models (Regression; Classification and Clustering;) and Evaluations (Recommender systems, collaborative filtering, association rules, optimization methods based on linguistic heuristics, as well as a myriad of methods for regression, classification, and clustering fall under the rubric of machine learning).
技術上,文本資料多了哪些工序?
- 前處理 Pre-processing (編碼處理,中文斷詞)
- 字串處理 String manipulation, esp. (linguistic) pattern extraction
- 語料庫 corpus 與詞庫 lexicon
複習
典型文本分析流程 a typical text analysis process:
- 蒐集與前處理 collecting raw text and preprocessing,
- 表徵 representing text,
- using Term Frequency-Inverse Document Frequency (TFIDF) to compute the usefulness of each word in the texts,
- word vectors
- 分類、分群、主題與關鍵詞偵測 categorizing documents by topics using topic modeling,
- 語意與情緒(情感)分析 semantic/sentiment analysis, and
- 應用導向的洞見與預測 gaining greater insights.
如何能?!語言學、語言資源 與 自然語言處理 !!
搭配語言學研究讓文本分析變得很厲害

語言資源 (Language Resources)
- 語料庫 corpus
- 詞庫 lexicon / lexical (knowledge) resources
- 知識本體 ontologies
語料庫概念
- From text to texts ?
- 語料庫 (Corpus) 是自然語言處理與文本解析的基礎建設。 a large collection of texts used for various purposes in Natural Language Processing (NLP).
- 標記 (annotation) 是核心。It’s linguistic in nature.
Good annotations support good applications
Corpus tools
KWIC, collocations (using \(\chi^{2}\) or likelihood ratio measures), etc.

Corpus systems

文本分析
方法論
- 文本的量化:統計分析與機器學習
- 文本的質化:詮釋、標記與敘事
文本的量化:統計分析與機器學習
文本的量化研究程序
(Benoit, 2016)

文本的量化:basic concepts

文本的量化:basic concepts

文本的量化: statistic analysis
- (corpus) sampling strategies
- Descriptive, distribution, correlation, regression, information theory, ….
Text representation
- bag-of-words
- document-feature matrix
- ngram, lexical chunks/bundles
- word vectors

自然語言處理和機器學習
Natural Language Processing and Machine Learning
自然語言處理 (計算語言學)
piped tasks
- [word-level] tokenization (and word segmentation), stemmer, POS tagger
> - [phrase-level] chunker, NER (Named Entity Recognizer)
> - [sentence-level] syntactic parser
> - [discourse-level] dialogue act
自然語言處理 (計算語言學)
Models and Evaluation
- 自然語言處理和機器學習是好盆友
- training and test data
- accuracy, precision, recall.
自然語言處理 (計算語言學)
Applications
Word embeddings (word2vec)


word2vec
R 的實作
tmcn.word2vectext2vec
Word embeddings for Discovering sense/sentiment changes

Word sentiment varies dramatically over historical time-periods
(Hamilton et al, 2016)
- Pathetic became more negative. It used to be similar in meaning to passionate but gained connotations of “weakness” over time.

Chinese Buddhist Texts


Deep learning (for everyone)
- somehow changed the game
- using R
文本的質化:詮釋、標記與敘事
Linguistic knowledge and annotation
inter-coder agreement, reliability 信度, validation 效度,
Pros and Cons
優點
- flexible; theoretically-motivated annotation/code frame effrots
- can apply to texts, speech, video, etc.
- 可以用來解決一般機器學習系統 high precision low recall 的問題。把潛在的語意與情緒發掘出來。
缺點
- manually intensive
- thus can be expensive
手工標記資料
- 最簡單可以用 Excel 來做:
- One (or more) column(s) for text data; One column for topic label (as
gold standard) - 通常至少有多於 3000 份標好的文件。
- One (or more) column(s) for text data; One column for topic label (as
- 大型的專案要考慮到永續、相容、交換等問題,建議使用標記系統。
- 語料庫和語言處理社群
GATE - 質性研究社群
CAT (Coding Analysis Toolkit) - lopetator
- 語料庫和語言處理社群
- labeling 和 annotation 的差異。
EDA and beyond
(Linguistic/Textual Data Science powered by NLP + Machine Learning)
掛上 power 的文本分析
- Text analytics / mining
- (Semantic and/with) Sentiment analysis
- Text learning (classification, regression, clustering,..)
- Text summarization and generation
- Text and multimodality
Textual DS: Steps
- 文本數據取得與前處理 data collection and preprocessing
- 文本探索分析 exploratory textual data analysis
- 文本語意表徵 converting text into a quantitative matrix;
- 文本分析機器學習 modeling the data: using quantitative or statistical methods to analyse this matrix in order to generate inferences about the texts or their authors.
- 文本分析結果表達、呈現與敘事
Step 1
數據取得與前處理 Data collection and preprocessing
- 決定語料文本的來源與樣本
- 決定要聚焦/移除的單位 identifying texts and units of texts for analysis;
- 定義要抽取/標記的特徵
- 自然語言處理協助 (automatic wordhood/pos/NER/sense tagging, dependency/lexical relation parsing,…)
心理與語言學家的警告
Stop words removal could be dangerous

Step 2
文本探索分析 Exploratory textual data analysis
- 抽取單位在文本中的量化特徵及其分佈 extracting from the texts quantitatively measured features—such as coded content categories, word counts, word types, dictionary counts, or parts of speech
- 形成假說
- 視覺化
Step 3
文本語意表徵 text semantic representation
Step 4
文本分析機器學習 text analytics and machine learning
Step 5
文本分析結果表達、呈現與敘事 Infovis, presentation and story-telling
注意:結構性作圖

非結構性數據作圖
Caveat
- 步驟之間是 back and forth
R ecosystem
tm,tmcnquanteda,preText,text2vecsyuzhet,sentimentr,tidytext,
實例:深度語意與情緒
- 文體、風格、民意、
總統的語言行為
Linguistic complexity / readability in President’s speech

- 川普的用字是否“低端”?

Wordcloud
中國總理

Wordcloud
台灣總統

台灣的 GDP 成長率 跟“經濟”關鍵字負相關?

換妳了
結語
A Bright Future for AHSS (Arts, Humanities and Social Sciences)?

Conclusion (never comes)
- hybrid mash-ups that pull from data/models
- 整合: 說的比較容易:需要從教育與學習破壞開始
- what are the celebrating skills does AHSSer develop?
KYLE (Knowledge-yielding Language Engineering)
知識導入語言工程團隊
