background-image: url(https://www.google.com/url?sa=i&source=images&cd=&cad=rja&uact=8&ved=2ahUKEwjRzoquzfrlAhULG6YKHTNMBMAQjRx6BAgBEAQ&url=%2Furl%3Fsa%3Di%26source%3Dimages%26cd%3D%26ved%3D%26url%3Dhttps%253A%252F%252Fwww.r-bloggers.com%252Ftext-mining-with-r-upcoming-courses-in-belgium%252F%26psig%3DAOvVaw258C0ZtAEUNQu49JmCdOhh%26ust%3D1574401601837249&psig=AOvVaw258C0ZtAEUNQu49JmCdOhh&ust=1574401601837249) background-position: center background-size: cover class: title-slide .bg-text[ # Introduction to Data Science with R ### week.11 <hr /> 11月 21, 2019 謝舒凱 ] --- # 期中烤後 <img src = './images/midterm_score.png' height="400px"></img> --- # 年齡不是問題 <img src = './images/midterm_score2.png' height="400px"></img> ??? birthday.R 安慰 --- # 注意 .large[ - 組別分好了就不要任意調動。以後就這樣坐了。 - 下週改成聽演講 (活動網站:https://linguistics.ntu.edu.tw/resources/ntue) ] 頂尖的計算心理語言學家  --- ## Text Analytics - see [reference slide](https://rlads2019.github.io/lecture/11/text.analytics.4.humanities.html#1) - From **text** to **corpus**. --- ## 先來個團體暖身練習 --- ## 文本分析基本流程 <img style='border: 1px solid;' width=80% src='./assets/img/tm001.jpg'></img> [source](https://manoharswamynathan.files.wordpress.com/2015/04/r-text-mining-001.jpg) --- ## What is Text Analytics ? .large[ - (**WHAT**): Text Analytics is the process of converting unstructured text data into meaningful data for analysis - (**WHY**) : to measure customer opinions, product reviews, feedback, to provide search facility, sentimental analysis and entity modeling to support fact based decision making, etc. - (**HOW**): combining many linguistic, statistical, and machine learning techniques. ] --- ## What is Text Analytics ? > It involves lexical analysis, categorization, clustering, pattern recognition, tagging, annotation, information extraction, link and association analysis, visualization, and predictive analytics. Text Analytics determines key words, topics, category, semantics, tags from the millions of text data available in an organization in different files and formats. The term Text Analytics is roughly synonymous with text mining. <center> <img style='border: 1px solid;' width=50% src='./images/Text-Analytics1.jpg'></img> </center> --- ## Text analytics flow - **Preparing / Preprocessing text and data**. - Text is unstructured or partially structured data that must be prepared for analysis. We extract features from text. We define measures. - Quantitative data are messy or missing, too They may require transformation prior to analysis. Data preparation consumes much of a data scientist’s time. - **Exploratory data analysis and Infographics** (data visualization for the purpose of discovery. We look for groups in data, find outliers, identify common dimensions, patterns, and trends.) - **Prediction models** (Regression; Classification and Clustering;) and Evaluations (Recommender systems, collaborative filtering, association rules, optimization methods based on linguistic heuristics, as well as a myriad of methods for regression, classification, and clustering fall under the rubric of machine learning). --- ## 搭配語言學研究讓文本分析變得很厲害 <img style='border: 1px solid;' width=60% src='./images/message.png'></img> --- ## Recap: Exploratory Data Analysis - 作圖與統計知識是兩把瑞士刀 - **統計**可以與**機器學習**一起學習。先思考作圖: - 什麼樣資料適合用什麼樣的圖形表達? - 適當的作圖工具(library)為何? - 如何**生動**、產生**互動**? - 建議學習順序:了解基本函數 `plot()` >> `ggplot2` >> **interactive plot** (`rCharts`, `plotly`, `networkD3`, `dygraphs`, `htmlwidgets`)... (視你的應用需求而定) --- ## 文本資料怎麼作圖? - 我們想要利用視覺化技術探勘文本中的訊息、趨勢、模式變化。例如 - 批踢踢語料中呈現的鄉民行為與社會網路 - 不同作者的書寫風格 - (選前選後的)政治觀點、主張、價值比較 - 基本的可能 - 文字雲 (word cloud) 與比較 - 關聯圖 (correlation plot) 與詞組樹 (phrase tree) - 調整字型 (custom fonts) 與風格 --- ## 文字雲 Word Cloud - A word cloud is simply a graphical representation in which the size of the font used for the word corresponds to its frequency relative to others. Bigger the size of the word, higher is its frequency. - `wordcloud2`, `RColorBrewer` 都可以。 --- ## 文字雲也可以比較 - To construct a **comparison cloud**, we require the data to be in the form of a term matrix. The `tm` package provides us with the `TermDocumentMatrix()` function that constructs a term document matrix: ```r #colnames(data) <- c("bush","obama") #comparison.cloud(data,max.words = 250, title.size = 2,colors = brewer.pal(3,"Set1")) ``` <img src="images/cloud.jpg" alt="Drawing" style="width: 400px;"/> --- ## 用 correlation plot 來觀察文本差異 <img src="images/coplot.jpg" alt="Drawing" style="width: 500px;"/> --- ## 詞組樹 - A phrase tree or a word tree provides useful insight into text as it provides a context and not just the frequency of words. <https://www.jasondavies.com/wordtree/> <img src="images/tree.jpg" alt="Drawing" style="width: 850px;"/> --- background-image: url(../img/emo/boredom-small.png) --- ## 再講一個 motion chart <iframe width="420" height="315" src="https://www.youtube.com/embed/6LUjgHPhxRw" frameborder="0" allowfullscreen></iframe> --- ## 從多變量量化語言學角度下的文本視覺化 Visualization of textual data (Ludovic Lebart and Marie Piron) <img src="images/dtm-vic.png" align="center" alt="Drawing" style="width: 600px;"/> --- ## 語言大數據發揮創意的話可以看到很多東西 [Google book ngram](https://books.google.com/ngrams/) <img src="images/gngram.png" alt="Drawing" style="width: 500px;"/> --- ## 用 R 玩看看 - [`ngramr`](https://github.com/seancarmody/ngramr): R package to query the Google Ngram Viewer ```r library(ngramr) # install locally! library(ggplot2) ggram(c("monarchy", "democracy"), year_start = 1500, year_end = 2000, corpus = "eng_gb_2012", ignore_case = TRUE, geom = "area", geom_options = list(position = "stack")) + labs(y = NULL) ``` 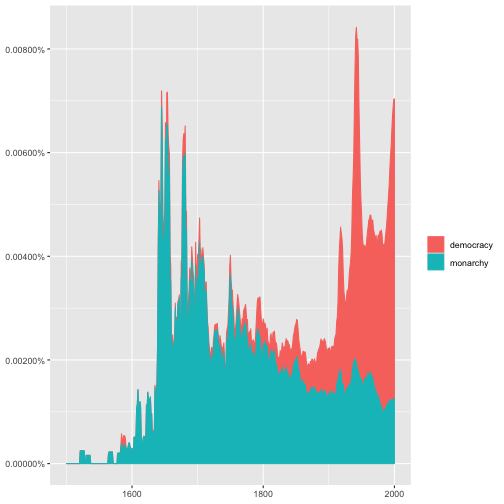<!-- --> --- ## 這個圖怎麼解釋 <img src="index_files/figure-html/unnamed-chunk-3-1.png" style="display: block; margin: auto;" /> <!-- --- --> <!-- ## 愛人與太太的消長 --> <!-- ```{r} --> <!-- # rownames(corpuses) --> <!-- ggram(c("愛人", "太太"), year_start = 1500, year_end = 2000, --> <!-- corpus = "chi_sim_2012", ignore_case = TRUE, --> <!-- geom = "area", --> <!-- geom_options = list(position = "stack"))+labs(y = NULL) --> <!-- ``` --> --- ## 回到 Text Analytics / Text Mining / Content Analysis 典型文本分析流程 a typical text analysis process: - 蒐集與前處理 collecting raw text and preprocessing, - 表徵 representing text, - using Term Frequency-Inverse Document Frequency (TFIDF) to compute the usefulness of each word in the texts, - word vectors - 分類、分群、主題與關鍵詞偵測 categorizing documents by topics using topic modeling, - 語意與情緒(情感)分析 semantic/sentiment analysis, and - 應用導向的洞見與預測 gaining greater insights. 如何能?!**語言資源** 與 **自然語言處理** !! --- ## 語言資源 (Language Resources) - 語料庫 corpus - 詞庫 lexicon / lexical (knowledge) resources - 知識本體 ontologies --- ## 語料庫:概念 - 語料庫 (Corpus) 是自然語言處理與文本解析的基礎建設。 a large collection of texts used for various purposes in Natural Language Processing (NLP). - 標記 (annotation) 是核心。It's linguistic in nature. > Good annotations support good applications --- ## 語料庫:工具 一般主要提供以下功能: - Corpus building and indexing - Concordance - Frequency list - (Grammatical) Collocations (and colligations) - Keywords - Thesaurus - ngram - Visualization --- ## 語料庫:工具 http://voyant-tools.org/?corpus=7fda0cccc3e3da40ce4f6b5c38347689 <img style = 'border: 1px solid;' width = 90%; src='./images/voyant.png'></img> --- ## 語料庫:網路服務 - 較具特色的(商用)系統:[Word Sketch Engine](https://www.sketchengine.co.uk/) - 較具特色的(開放)系統 [COPENS](http://140.112.147.125:8000/)/pttCorpus <- 敝帚自珍 <img style='border: 1px solid;' width=80% src='./images/wse.png'></img> --- ## R 生態提供什麼樣的文本分析資源工具? - `tm`, `tmcn`, `tidytext` (搭配線上書 [Tidy Text Mining with R](http://tidytextmining.com/)) - 語言學家的實作:`quanteda` ([Quantitative analysis of Textual Data](http://quanteda.io/)), `corpus` ([introduction](http://corpustext.com/articles/corpus.html)), `koRpus`, `zipfR`, `stylo`([Stylometry with R](https://sites.google.com/site/computationalstylistics/)).... [比較](http://docs.quanteda.io/articles/pkgdown_only/comparison-packages.html) - 中文社群:`jiebaR`, `tmcn`, `chinese.misc`, `Rweibo`,... `pttR`(?!!) --- ## Group Exercise ```r #魯迅:阿 Q 正傳 luxun <- scan("http://www.gutenberg.org/files/25332/25332-0.txt", what="char", sep="\n") # another lazy way require(gutenbergr) luxun <- gutenberg_download(25332) mixSeg <= luxun$text luxun.seg <- segment(luxun$text, mixSeg) write.table(luxun.seg, 'luxun.txt') ``` --- ## Group Exercise - Download a Chinese novel (except 魯迅:阿 Q 正傳) from Gutenberg website, clean and preprocess the text (incl. using `jiebaR()` to segment the text). - Create a sorted word-freq list. - Add a POS column (using `jiebaR()` again) to the list and write it to a file. - Extract all the **pronouns** (labeled as `r`), count the occurrences separately, make the table and plot. <!-- --- --> <!-- # --> <!-- --- --> <!-- ## `JiebaR` --> <!-- - 先使用 `worker()` 初始化分詞引擎。 --> <!-- ```{r, results='hide', warning=FALSE, message=FALSE} --> <!-- library(jiebaR) --> <!-- library(jiebaRD) --> <!-- mixSeg <- worker() --> <!-- #hmmSeg <- worker(type = "hmm") --> <!-- text2 <- "總有一天你會醒來,告訴我一切都是假的" --> <!-- #segment(text2, mixSeg) --> <!-- # 或是利用分詞運算子 <= --> <!-- mixSeg <= text2 --> <!-- #segment(".\\data\\test.txt", mixSeg) --> <!-- ``` --> <!-- --- --> <!-- ## `JiebaR`: 客製化 custimization --> <!-- ```{r,echo=TRUE, eval=FALSE} --> <!-- mixSeg --> <!-- # $user --> <!-- # "/Library/Frameworks/R.framework/Versions/3.2/Resources/library --> <!-- # /jiebaRD/dict/user.dict.utf8" --> <!-- ``` --> <!-- --- --> <!-- ## `JiebaR`: POS tagging --> <!-- (POS tagset: [ICTCLAS 漢語詞性標註集](http://www.cnblogs.com/chenbjin/p/4341930.html)) --> <!-- ```{r} --> <!-- pos.tagger <- worker("tag") --> <!-- pos.tagger <= text2 --> <!-- ``` --> <!-- --- --> <!-- ## `JiebaR`: Keywords Extraction and Similarity Calculation --> <!-- - `Simhash` algorithm --> <!-- ```{r} --> <!-- key.extract <- worker(type = "keywords", topn = 1) --> <!-- key.extract <= text2 --> <!-- sim <- worker(type = "simhash", topn = 2) --> <!-- sim <= text2 --> <!-- ``` -->